XII. Télédétection
XII.3 Classification non supervisée
- Qu'est-ce qu'une classification non supervisée ?
- Prise en main des données
- Extraction des signatures spectrales
- Classification non supervisée au moyen de la méthodes des K-Means
L'objectif de ce chapitre est de réaliser une classification, c'est-à-dire de partir d'une image satellite pour obtenir une couche d'occupation du sol avec différentes catégories.
Pour cela, nous allons utiliser une image Sentinel-2 du Sud de l'Inde. Nous commencerons par explorer cette image et ses signature spectrales, comme vu ici et là, avant d'effectuer une classification non supervisée par la méthode des K-Means pour en extraire l'occupation du sol.
Qu'est-ce qu'une classification non supervisée ?
Un peu de théorie avant de commencer ! Une classification a pour but de partir d'une image pour en regrouper les pixels sous forme de catégories. Typiquement, on va partir d'une image satellite pour arriver à une couche d'occupation du sol avec par exemple 4 catégories : surface en eau, sol nu, forêt, cultures. Bien sûr, les catégories vont varier suivant l'image et l'objectif.
On va distinguer 2 grands types de classification : supervisée ou non supervisée. Nous allons voir dans ce chapitre un exemple de classification non supervisée, c'est-à-dire uniquement basée sur les traitements statistiques de l'image, sans recours à un échantillonnage terrain. En gros c'est le logiciel qui fait tout le travail, ce qui a comme vous vous en doutez des avantages et des inconvénients !
L'hypothèse de travail est que les objets de l'image ayant une signature spectrale identique ou similaire appartiennent à la même classe d'occupation du sol.
Il existe plusieurs algorithmes de classification non supervisée :
- le regroupement par moyenne-K (K-Means, que nous allons voir ici)
- le regroupement par ISODATA
- ...
Pour en savoir plus sur les classifications, vous pouvez vous rendre sur le tutoriel du Centre canadien de cartographie et d’observation de la Terre.
Prise en main des données
L'image que nous allons utiliser est une image Sentinel-2 du Sud de l'Inde d'avril 2020.
Ouvrez un nouveau projet QGIS et ajoutez-y l'image geotiff S2A_20200401.
Pour voir où se situe la zone, ajoutez par exemple un fonds OpenStreetMap.
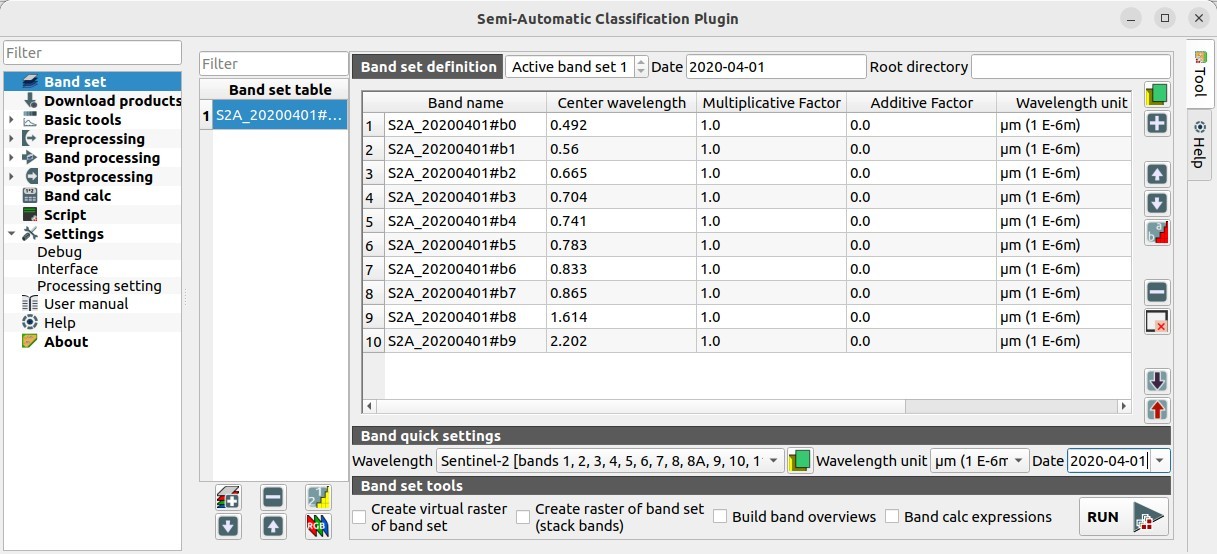
Cette image ne possède que 10 bandes et non 13 comme normalement les images Sentinel 2. Les bandes 1 (corrections atmosphériques à 60m), 9 et 10 (bandes d'estimation de la vapeur d'eau dans l'atmosphère, à 60m) ont été enlevées.
Si on reprend la liste des bandes d'une image Sentinel 2, la correspondance se fait donc ainsi :
| Numéro de bande | Bande Sentinel-2 |
|---|---|
| - | Bande 1 - Aérosol côtier |
| 01 | Bande 2 - Bleu |
| 02 | Bande 3 - Vert |
| 03 | Bande 4 - Rouge |
| 04 | Bande 5 - Végétation "red edge" |
| 05 | Bande 6 - Végétation "red edge" |
| 06 | Bande 7 - Végétation "red edge" |
| 07 | Bande 8 - PIR |
| 08 | Bande 8A - PIR "étroit" |
| - | Bande 9 - Vapeur d'eau |
| - | Bande 10 - SWIR - Cirrus |
| 09 | Bande 11 - SWIR |
| 10 | Bande 12 - SWIR |
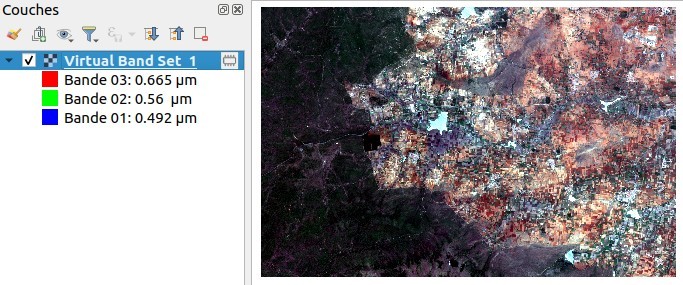
Pour explorer cette image, nous pouvons tester différentes compositions colorées.
Commençons par une composition colorée "en vraie couleur", avec les bandes rouge-vert-bleu, soit les bandes 3-2-1 :
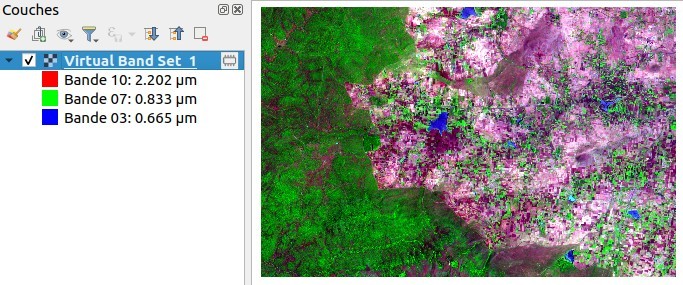
On peut aussi tester des compositions en fausse couleur.
Avec les bandes PIR-R-Vert (7-3-2 ici), on observe la végétation en rouge :

Avec les bandes IRM-PIR-R (10-7-3 ici), on observe plutôt les sols nus, la végétation et l'humidité :
Extraction des signatures spectrales
Nous allons maintenant extraire les signatures spectrales des 4 types d'occupation du sol suivants :
- Surface en eau
- Surface en forêt
- Surface en sol nu
- Surface en cultures
Ce serait bien de fournir un couche scp exemple avec les ROI, ou de montrer des captures d'écran. Je ne sais pas trop quoi choisir pour les cultures par exemple !
Pour cela, vous pouvez vous référer ici.
N'oubliez pas de définir le jeu de bandes comme l'image S2A_20200401 !
Interprétation des signatures spectrales ?
Pq a-t-on besoin de regarder les signatures spectrales si on fait une classif non supervisée ?
Classification au moyen de la méthodes des K-Means
K-Means : comment ça marche ?
La méthode des K-Means ou K-moyennes est une méthode de clustering utilisée pour regrouper des individus (dans notre cas, des pixels), de manière à ce qu'au sein de chaque groupe les individus se ressemblent le plus possible, et que les groupes soient le plus différents possibles les uns des autres.

Cette méthode est utilisée en télédétection mais également dans beaucoup d'autres domaines !
Cette méthode nécessite que l'utilisateur détermine au préalable un nombre de classes. Elle se déroule en plusieurs étapes :
- Choix au hasard d'un point par classe (si l'utilisateur a choisi d'utiliser 4 classes, 4 points seront tirés au sort). Ces points constitueront le centre des classes.
- Chacun des autres points sont affectés au centre le plus proche : on constitue ainsi par exemple 4 classes.
- Les barycentres de chacune de ces classes sont calculés
- Et on recommence ! Chaque point est affecté au centre le plus proche, et ainsi de suite. On arrête quand les points ne changent plus de classe (en théorie tout au moins, en pratique on peut être obligé d'arrêter avant pour limiter le temps de calcul).
Toutes ces étapes sont effectuées par le logiciel, l'utilisateur se bornant à spécifier un nombre de classes.
Au final, la méthode des K-Means est rapide et son principe est simple. Cependant, elle nécessite de fixer à l'avance un nombre de classes, et ne donnera pas 2 fois le même résultat si on la lance avec les mêmes paramètres, les centres de chaque classe étant déterminés de manière aléatoire lors de la première itération.
Une manière de contourner la première de ces limitations est de définir un grand nombre de classes, pour les regrouper ensuite manuellement. C'est ce que nous allons faire ici !
Mise en pratique sur l'image Sentinel-2
Le jeu de bande doit bien être défini au préalable dans l'extension SCP.
Menu SCP → Traitement de bande → Clustering
 :
:
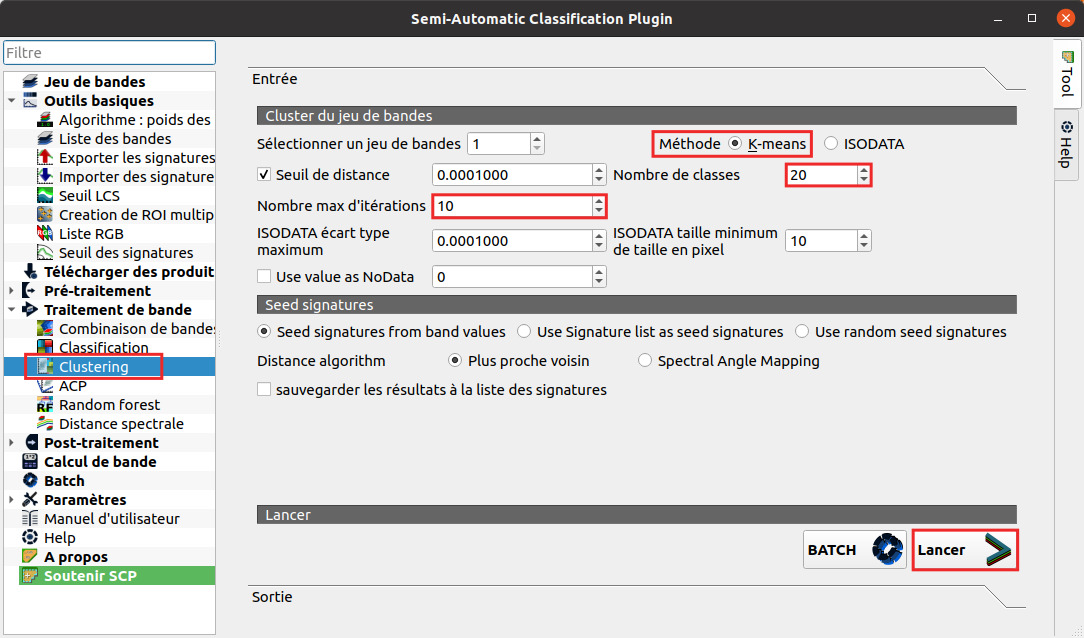
Les principaux paramètres à définir ici sont les suivants :
- Méthode : K-Means (la méthode ISODATA est une autre méthode de classification non supervisée basée sur celle des K-Means)
- Nombre de classes : choisir 20, nous procéderons ensuite à des regroupements pour arriver à 4 classes finales
- Nombre max d'itérations : il s'agit du nombre d'itérations de la méthode (voir plus haut). L'idéal est de fixer un nombre d'itérations assez élevé, 50 par exemple, mais le temps de calcul peut être assez important. Vous pouvez tester avec par exemple 10 itérations, et relancer avec un nombre plus important si le temps de calcul n'est pas trop élevé, en fonction de votre ordinateur !
D'autres paramètres peuvent également être définis (pour rappel, vous pouvez vous référer à la documentation de SCP pour aller plus loin) :
- Seuil de distance : si les points ne sont plus déplacés qu'à une distance inférieure à ce seuil, l'algorithme prendra fin sans autre itération. Si ce seuil n'est jamais atteint, l'algorithme effectuera le nombre d'itérations choisi
- ISODATA écart-type maximum et ISODATA taille maximum de classe en pixels : ces 2 paramètres sont uniquement utilisés pour une classification ISODATA
- Use value as NoData : permet de spécifier une valeur de pixel qui sera ignorée lors des calculs
- Seed signatures from band values / Use signature list as seed signature / Use random seed signatures : il faut choisir une de ces 3 options afin de déterminer la manière dont seront choisis les centres de classes lors de la première itération.
- Distance algorithm : cet algorithme définit comment la distance entre les points est calculée, il peut s'agir simplement de la distance euclidienne avec plus proche voisin, ou de la distance spectrale avec Spectral Angle Mapping
- Sauvegarder les résultats à la liste des signatures : si cette case est cochée, les signatures spectrales des futures classes seront ajoutées à celles des ROI
Pas trop sûre de l'explication sur les 3 options pour choisir la manière dont seront déterminées les centres des classes la 1ère fois !
Une fois vos paramètres choisis, cliquez sur le bouton Lancer en bas de la fenêtre. Choisissez le nom et l'emplacement de l'image GeoTIFF qui sera créée en sortie, et patientez... (une barre de progression est visible en haut de la fenêtre de QGIS)
Dans la fenêtre SCP s'affiche maintenant un tableau comportant une ligne par classe, et 3 colonnes :
- La première colonne correspond à l'identifiant de la classe
- La deuxième colonne indique la signature spectrale de chaque classe, avec une valeur par bande
- La troisième colonne indique la distance au centre de la classe
L'image en sortie est automatiquement ajoutée à QGIS.
C'est un premier résultat, qui est peu lisible à cause du grand nombre de classes. L'étape suivante est donc d'opérer des regroupements de classes manuellement, afin d'obtenir une image plus lisible.
Reclassification : regrouper des classes pour y voir plus clair
Notre objectif sera ici de regrouper des classes pour n'en obtenir que 4 :
- Surface en eau
- Surface en sol nu
- Surface en forêt
- Surface en cultures
Nous allons utiliser pour cela l'outil de reclassification de l'extension SCP.
Si vous n'avez pas fermé la fenêtre SCP après avoir généré le résultat de la classification, vous pouvez accéder à l'outil de reclassification dans la rubrique Post-traitement → Reclassification ; sinon menu SCP → Post-traitement → Reclassification.
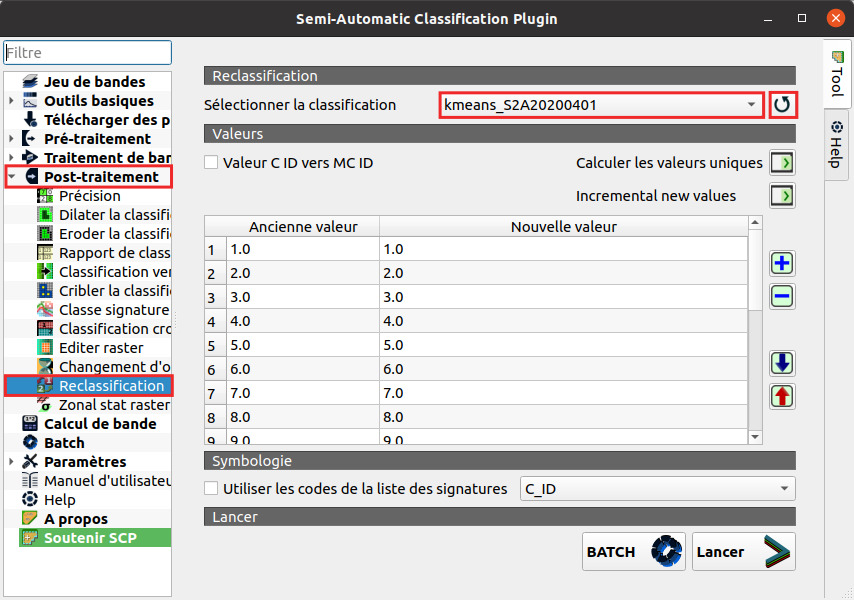
- Il faut d'abord actualiser la liste des images disponibles en cliquant sur le bouton avec une flèche en haut à droite de la fenêtre
- Vous pouvez maintenant sélectionner l'image créé par la classification K-means dans la liste déroulante
- Cliquez ensuite sur le bouton Calculer les valeurs uniques pour faire apparaître une ligne par classe (si vous avez suivi l'exemple, il y en aura donc 20) dans le tableau
Valeur C ID vers MC ID : pas utilisé pour K-means puisque pas de hiérarchie pour ce type de classif
chapitre précédent chapitre suivant
haut de page